Distributed Mutual Exclusion
Distributed Mutual Exclusion Introduction
To maintain mutual exclusion among n distributed processes/machines/nodes
while (true){
Perform local operations
acquire()
execute critical section
release()
}
During critical section, the machines can interact with remote processes or manipulates shared memory
Properties of Distributed Mutual Exclusion
Safety
Safety means that only one process is allowed to access the shared resource at a time, preventing concurrent access that could lead to data corruption or unexpected behavior.
To ensure safety, a distributed mutual exclusion algorithm should guarantee that, at any given moment, either no process is in the critical section or only one process is in the critical section.
Liveness
liveness guarantees that the system does not deadlock or remain in a state where no process can make progress indefinitely.
Fairness
Fairness ensures that processes requesting access to the shared resource are treated fairly in terms of granting access. It prevents situations where a particular process is continually granted access to the critical section while others are repeatedly denied, leading to potential starvation or unfairness.
fairness means that every process that requests access to the critical section should eventually be granted access, and no process should be unfairly prioritized over others.
There is a bounded wait time and request should be served in the order of request time
Other Expectations
- Minimize message traffic
- how many exchange of messages needed
- minimize synchronization delay
- if a machine requests a lock and no one else is
holdingthe lock, then the machine shouldquicklyget the lock - Approximate(optimistically): No other machine is waiting for the lock
- Switch quickly between processes waiting for lock
- if a machine requests a lock and no one else is
Assumptions
- The network is reliable
- All messages sent get to their destination eventualy
- Not realistic, we will get to that later in the course
- The network is asynchronous
- Messages may take long time
- Machines may fail at any time (not all protocols handle it in its vanilla form)
General Idea
Entry: Before entering critical section, a machine must get permission from other machinesExit: When exiting critical section, a machine must let the others know that he has finished executing the critical sectionReceving request: For fairness, machines allow other machines who had asked for permission earlier than them to proceed
Centralized lock server
Entry: Send REQUEST to central server and wait for permissionOn receving the request: Server puts it in the queue and delay sending response back to process until process is at the head of queu (FIFO)Exited: Once the critical section is executed, the machine sends a RELEASE message to the central lock serverOn Receiving a request: Removes the machine from the queue after it gets released
Disadvantages
- One server,
one-point of failure- The server goes wrong and everything goes for a toss
- The centralized lock server quickly becomes a
performance bottleneck - Requires the
electionof a centralized server- According to some coordinator election algorithm discussed in the last lecture
Ring-base protocol
Machines are logically structured in a ring and a token is passed along the ring and only the machine with the token can execute the critical section.
If a machine wants to enter critical section it holds on to the token and only forward to the next node after the execution is completed
Property analysis
| Property | Explanation |
|---|---|
| Safety | Distributed mutual exclusion ensures safety by only allowing the machine with the token to execute the code. This guarantees that only one process can access the critical section at a time, preventing race conditions and ensuring correctness. |
| Liveness | The liveness of distributed mutual exclusion depends on the worst-case scenario where a process has to loop through the entire ring before acquiring the lock. In this case, it may take a significant amount of time for a process to be able to enter the critical section, potentially impacting system performance and responsiveness. Therefore, liveness may be compromised in certain situations. |
| Fairness | Distributed mutual exclusion does not guarantee fairness as it does not take into account when requests come in or where the token is currently located. Consequently, processes that are further away from the token or have recently made requests may have to wait longer before being able to acquire the lock, resulting in an unfair distribution of resources. Hence, fairness is not guaranteed in this scenario. |
Fair Ring base protocol
The token now contains the timet for the earliest known, yet outstanding request
Entry of critical section
Upon receiving the token, there are 3 cases that might be happening
Assuming
- There is another machine that requested to enter before the current machine
- Forwards the token
- The machine start the request earlier than the earliest known
- assigning
forward the token since we do not know if there exists an earlier on other nodes
- assigning
forward the token since we do not know if there exists an earlier on other nodes
- assigning
- Hold the token, execute critical section
- Reset
- Forward the token
| Property | Explanation |
|---|---|
| Safety | Safety is ensured in the fair ring-based mutual exclusion algorithm. This means that only one process can access the critical section at a time. When a process wants to enter the critical section, it sends a request message to its neighbor and waits for acknowledgment before proceeding. This ensures that no multiple processes can concurrently access the critical section, ensuring safety. |
| Liveness | The fair ring-based mutual exclusion algorithm does not guarantee liveness as it introduces an additional loop for passing the token. This extra loop can result in delays and potential deadlocks if a process fails or takes too long to release the token. Therefore, there is no guarantee that every process eventually gets access to the critical section, making it worse than the unfair version of the ring-based algorithm in terms of liveness. |
| Fairness | The fair ring-based mutual exclusion algorithm ensures fairness by using a token passing mechanism. Each process holds a token that determines its turn to enter the critical section. The token circulates around the ring, and when a process receives the token, it can enter the critical section if it has requested access. If a process does not want to enter the critical section, it passes the token to its neighbor. This ensures that every process gets an equal opportunity to access the critical section, making it fair among all processes participating in the distributed system. |
Lamport's Shared Priority Queue
Each machine maintains locally a queue a part of shared priority queue
If a machine wants to run a critical section
- it must have replies from all other machines
- The request to run critical section must be at the front of the local queue
Guaranteed properties
- All other machines are aware of the request of a machine's request to enter critical section
- each machine is aware of any earlier request
Enter the critical section
- Stamp the request to enter with the current time T
- Add the request to local queue
- Broadcast
Req(T)to all other machines Req(T)also records who have responded the request- Wait until
- Receive all replies from all other machines
Req(T)reaches the front of the local queue
Exiting Critical section
- Base on who has reply that is stored, when exiting the critical section, it will release the lock and broadcast
RELEASEmessage to the rest of the machine Popthe head of the queue
Receiving a acquire request
When a machine receive a request from other machine to carry out critical section
- It checks if there is any outstanding request locally
- If no,
- append the request to the queue
- reply that it can enter
- if yes
- Hold on the reply
Receiving the release request
pop the head of the queue
Multiple Nodes Requesting
Property analysis
Safety analysis
Base setup machine P1 made request and P2
| Property | Explanation |
|---|---|
| Safety | Yes, |
Optimised Version
Steps
- When a node receives a reply, and it does not have any earlier outstanding request, it will simply
replybut will not store the request in the priority queue. - Once a node receives all the reply from the rest of the node, it will start execution
- After executing critical section, it will pop the head of the queue
- Then it sends a reply to the rest of the outstanding request in the queue and clears the queue
Property Analysis
Safety:
Caveats
It does not handle fault tolerance
a node can only proceed if it receive a reply
Voting Protocol
Idea
- Machines VOTE for which other machine can go to critical section
- A machine can VOTE only once at any given time
- A machine can enter the critical section only if has a
majorityof VOTEs
Properties
- At most one process can have the majority of the
VOTEsat any given time
Steps
- Broadcast request
- Wait for majority of VOTEs to arrive
- Critical section execution
- Release votes back
This is fault tolerance
Simple case
Complex case
When the machine receive the request, it will check if it has voted before, if yes then it will put the request in a queue
When release vote is received, it will vote the top node in the queue
Problem
Deadlock
Property analysis
| Property | Explanation |
|---|---|
| Safety | Mutual exclusion but deadlock |
| liveness | Max RTT Amount the fastest n/2+1 machine |
| Fairness | No |
Dead lock prevention
- Timestamp each request with the current time(logical clock)
- On receipt of Request(T)
- If already
VOTEDfor REQUEST(T') and T' is later than T, then sendRESCIND-VOTEto the machine requesting REQUEST(T')
- If already
- On receipt of RESCIND-VOTE:
- It has not enter critical section, it
RELEASEthe vote - If it enter Critical section, wait for end of cs to release the vote
- It has not enter critical section, it
Case 1: P1 has not enter critical section
Case 2: P1 In the midst of critical section
Advantages
It is fault tolerant than other of the protocols discussed previously. it works even when (N/2-1) machines are down in the network
Maekawa Voting Protocol
The goal is to reduce the number of messages during the collection and release of VOTEs
It is not necessary to broadcast the REQUEST message. Instead each machine can have its own VOTING Set, sends requests within this set and collects VOTEs only from the machines in its VOTING set.
Design
- The safety of the protocol depends on the construction of VOTING set.
- Let us assume that the VOTING set of machine “i” is captured via “Vi”. For any 1<=i,j<=N, we must have “Vi ∩ Vj ≠ ϕ”.
- Intuitively, for any two machines “i” and “j” must have
overlappingVOTING sets so that at least one machine in the VOTING sets will VOTE foreither “i” or “j”, but NOT both.
Design Voting set
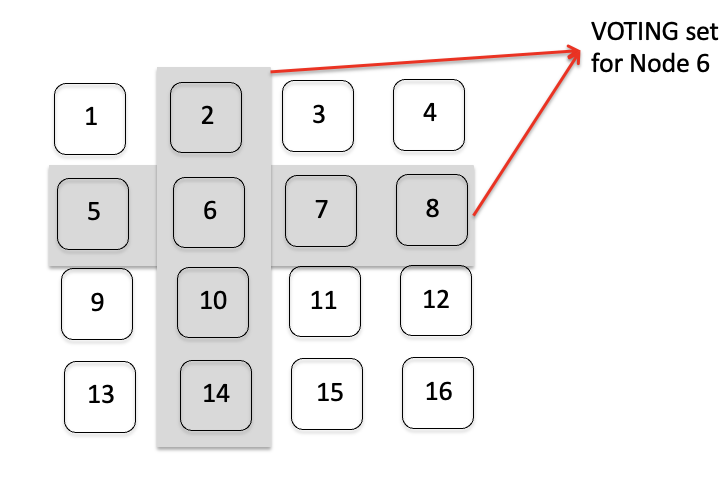
what is the number of VOTEs to be collected before a machine can enter critical section?
All the nodes in the voting set have to reply
It is kind of fault tolerant, because it does not require entire system's nodes to be alive, but it require all the machines in the voting set to the alive
What is the total number of messages exchanged
No. Request + No. votes + No. release
Quiz
Consider the basic version of the voting protocol (i.e., without deadlock prevention) with five (5) nodes. Assume two out of these five nodes, say N1 and N2, wish to enter the critical section concurrently. N1 receives three votes and N2 receives two votes.is it possible for N3/N4/N5 to have two requests of N1 in the queue? if no provide a example to proof
No, it is not possible for N3/N4/N5 to have two requests of N1 in the queue.
Let's understand this by breaking down the voting protocol of distributed mutual exclusion:
- When a node (say N1) wants to enter a critical section, it sends a request to all nodes in the system.
- On receiving a request, each node gives its vote to one request at a time using some priority rules (e.g., based on timestamps).
- A node is allowed to enter the critical section when it has received votes from a majority of nodes in the system.
In this scenario, N1 and N2 are trying to enter the critical section concurrently. N1 receives three votes and N2 receives two votes. So, N1 will be allowed to enter into the critical section.
Now, let's consider your question: is it possible for any of the remaining nodes (N3/N4/N5) to have two requests from N1 queued up?
No, because:
- In order for a node (N1) to send another request while its previous one hasn't been completed yet, it would need to exit and then re-enter the critical section.
- However, before exiting, it must release its votes - which means sending a release message to all other nodes.
- Only after receiving this release message can other nodes process new requests from that node.
Hence, until N1’s current request is processed completely (i.e., until it exits from CS and releases its votes), no other node can have another request from N1 in their queue.
Example: Assume that Node 1 (N1) has sent two consecutive requests R1 and R2 respectively. After sending R1, before N3/N4/N5 could process R2 they must first receive a release message for R1 from N1. Therefore at any given moment, there can only be one request from N1 in their queue. Thus, two requests from the same node cannot exist simultaneously in the queue of N3/N4/N5.
No, it's not possible for N3/N4/N5 to have two requests of N1 in the queue. According to the voting protocol, a node (N1 in this case) will send a request message to all other nodes only once when it wants to enter the critical section. It will not send another request message until it has exited the critical section. Therefore, each of these nodes (N3/N4/N5) can only have one request from N1 in their queue at any given time.
For voting protocol, does the when a node finish execution of critical section, it release the votes but does it pop the request from other nodes's queue who did not vote for it
In a distributed mutual exclusion system using the voting protocol, when a node finishes execution of its critical section, it does indeed release the votes it has acquired. However, it does not directly pop or remove requests from other nodes' queues who did not vote for it.
The responsibility of managing and updating its own request queue falls on each individual node. Once a node receives a release message from the node that has just exited its critical section, this triggers the former to update its own queue by removing the corresponding request.
Therefore, while the exiting node initiates this process by sending out release messages, it's up to each recipient node to then handle its own queue management in response.
By design, ring-based protocol for mutual exclusion is not fault tolerant. Design a simple protocol to make the ring-based protocol fault tolerant. Specifically, discuss the following: 1) messages sent and received and the protocol to handle them, 2) how to handle nodes leaving the network, 3) how to handle nodes joining the network, 4) how to handle intermittent faults.
Designing a fault-tolerant ring-based protocol for mutual exclusion involves ensuring that the system can handle failures and can recover to a normal state even when some of its components fail.
- Messages sent and received and the protocol to handle them:
In a basic ring-based protocol, nodes exchange two types of messages: REQUEST and RELEASE. In our fault-tolerant protocol, we will introduce an additional message type: HEARTBEAT.
- REQUEST: This message is sent by a node that wants to enter the critical section. It includes the ID of the requesting node.
- RELEASE: This message is sent by a node after it has finished executing in the critical section.
- HEARTBEAT: This message is periodically broadcasted by each node to signal that it's still active.
If a node receives a REQUEST message and it's not currently in or waiting for the critical section, it forwards the request to its successor. If it receives a RELEASE message, it removes the corresponding request from its queue and forwards the release message.
- How to handle nodes leaving the network:
When a node leaves (either voluntarily or due to failure), its predecessor needs to establish contact with its successor. To facilitate this, each node maintains information about both its predecessor and successor in the ring.
Periodically, each node sends out a HEARTBEAT message; if several consecutive heartbeats from any given node are not received, that node is assumed to have left or failed. The predecessor of this presumed-failed node then establishes contact with its next known active successor in order to maintain continuity in the ring.
- How to handle nodes joining the network:
When a new node wants to join, it sends a JOIN request to any one of the existing nodes. That existing node responds with information about itself and its current successor. The new node then positions itself between these two nodes by updating their predecessor/successor information appropriately.
- How to handle intermittent faults:
Intermittent faults can be handled by a combination of heartbeat messages and temporary reconfiguration of the network. If a node doesn't respond to several consecutive heartbeats, it's assumed to be faulty and temporarily removed from the network. Once it starts sending heartbeats again, it can be reintegrated into the network using the same protocol as for joining nodes.
To ensure data consistency, any changes made in the critical section during the fault period should be broadcasted or sent directly to the reintegrated node before it can enter the
1. Consider Lamport’s shared priority queue protocol for distributed mututal exclusion without Ricart and Agrawala’s optimization. You have three machines P1, P2 and P3, none of which is malicious. Let us assume P1 and P2 request to enter the critical section concurrently. Is it possible to encounter a scenario where the following happens: Upon receiving the RELEASE message from P2, machine P3 removes the request of P1 from P3’s priority queue. If the scenario is impossible, then provide a proof. If the scenario is possible, then draw a sequence diagram or discuss the scenario point-by-point as it happens. You may assume that the network layer does not drop any message.
The scenario described is impossible according to Lamport’s shared priority queue protocol for distributed mutual exclusion. The reason is that the protocol works in a way that each machine maintains a priority queue of requests based on the timestamp of the request and the id of the machine. The machine with the smallest timestamp (i.e., earliest request) is given priority and if two machines have equal timestamps, then the one with smaller id is given preference.
In this scenario, P1 and P2 request to enter the critical section concurrently. According to Lamport's algorithm, all machines, including P3, will add these requests to their priority queues as they receive them. The order will depend on their timestamps and ids.
When P2 exits from its critical section, it sends a RELEASE message to all other machines in the system including P3. Upon receiving this RELEASE message from P2, P3 will only remove P2’s request from its priority queue because this message serves as an indication that P2 has finished executing its critical section and therefore its request can be safely removed from other machines' queues.
However, this does not affect P1's request in any way because it was not P1 who sent the RELEASE message but rather it was from P2. So, even after receiving RELEASE message from P2, machine P3 cannot remove the request of machine P1 from its queue because it has not received a RELEASE message for that specific request i.e., from machine P1.
Therefore, there is no possible scenario where upon receiving a RELEASE message from one machine (P2), another machine (P3) removes a different machine's (P1) request from its queue. Thus proving that such scenario is impossible under Lamport’s shared priority queue protocol for distributed mutual exclusion without Ricart and Agrawala’s optimization.